
OpenAI lanza los modelos GPT‑4.1, GPT‑4.1 mini y GPT‑4.1 nano
OpenAI lanzó tres nuevos modelos de inteligencia artificial: GPT‑4.1, GPT‑4.1 mini y GPT‑4.1 nano. Estas versiones mejoradas superan a sus predecesores en generación de código, seguimiento de instrucciones y comprensión de contextos largos, ofreciendo además una mayor eficiencia y costos reducidos. Con una ventana de contexto ampliada hasta 1 millón de tokens y una base de conocimientos actualizada hasta junio de 2024, estos modelos están disponibles exclusivamente a través de la API de la compañía.
El modelo principal, GPT‑4.1, destaca por su rendimiento en tareas de codificación, superando en un 21% a GPT‑4o y en un 27% a GPT‑4.5 en evaluaciones estándar. Las versiones mini y nano ofrecen soluciones más económicas y rápidas, manteniendo un alto nivel de desempeño, lo que las hace ideales para una amplia gama de aplicaciones, desde agentes autónomos hasta análisis de grandes volúmenes de datos.
A continuación, analizamos el desempeño de los tres modelos en distintas áreas, con ejemplos reales.
Desempeño en generación de código: precisión y eficiencia mejoradas
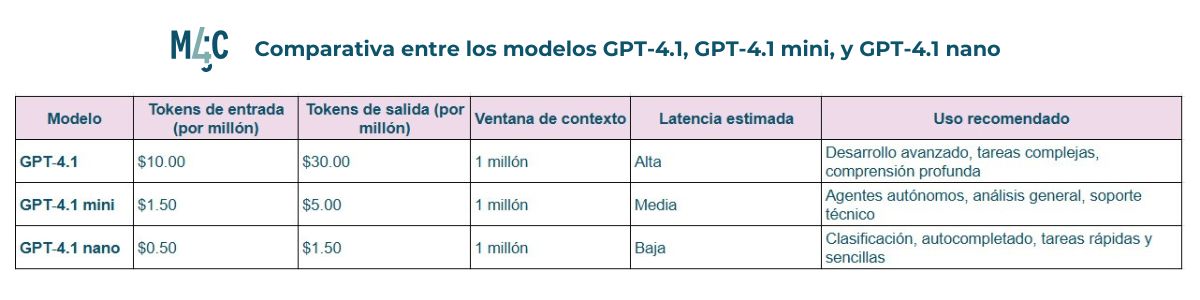
GPT‑4.1 ha sido específicamente optimizado para superar retos reales en ingeniería de software. En la evaluación SWE-bench Verified (métrica que evalúa la capacidad de resolver tareas a partir de descripciones de incidencias en repositorios de código, generando parches funcionales y validados), este modelo alcanzó un 54,6% de efectividad, comparado con el 33,2% de GPT‑4o, lo que representa una mejora absoluta del 21,4%.
Entre las mejoras destacadas, GPT‑4.1 demuestra mayor consistencia al usar herramientas, mejor seguimiento de formatos diff, y una notable reducción en ediciones innecesarias. Estas habilidades lo hacen más confiable para tareas como codificación frontend, desarrollo basado en agentes y refactorización de archivos grandes (una práctica común en desarrollo de software para reorganizar y optimizar el código dentro de archivos extensos sin cambiar su funcionalidad externa).
GPT‑4.1 mini, a pesar de su tamaño reducido, iguala o supera a GPT‑4o en evaluaciones de inteligencia, reduciendo la latencia casi a la mitad y el costo en un 83%.
Finalmente, GPT‑4.1 nano, el modelo más rápido y económico, logró una puntuación de 9,8% en la prueba Aider polyglot coding (un benchmark diseñado para evaluar la capacidad de los LLMs en la edición y generación de código en múltiples lenguajes de programación), superando a GPT‑4o mini, lo cual es impresionante considerando su tamaño y velocidad. Además, obtuvo una puntuación del 80,1% en MMLU (mide la comprensión del lenguaje y el conocimiento multitarea) y del 50,3% en GPQA (mide la capacidad de razonamiento profundo en física), lo que la convierte en una opción ideal para tareas como clasificación y autocompletado.
Estas mejoras permiten a los desarrolladores crear aplicaciones más eficientes, desde asistentes de codificación hasta sistemas de revisión automática de código, facilitando la integración de inteligencia artificial en procesos de desarrollo de software.
Por ejemplo, durante una demostración, GPT‑4.1 fue capaz de desarrollar una aplicación de tarjetas educativas (conocidas como flashcards) para el aprendizaje de idiomas, siguiendo instrucciones detalladas y adaptándose a las necesidades específicas del usuario.
Más fiabilidad y comprensión en el seguimiento de instrucciones
GPT‑4.1 mejora de forma significativa su capacidad para seguir instrucciones, superando ampliamente a versiones anteriores como GPT‑4o, especialmente en tareas complejas. Esta mejora se ha medido mediante una evaluación interna desarrollada por OpenAI, centrada en 6 áreas:
- Formato personalizado: genera respuestas en estructuras como XML, YAML o Markdown.
- Instrucciones negativas: evita comportamientos explícitamente prohibidos.
- Órdenes secuenciales: respeta la secuencia exacta de pasos que se indican.
- Requisitos de contenido: asegura la inclusión de información obligatoria.
- Clasificación: organiza datos según criterios concretos (como población).
- Gestión de incertidumbre: responde con «no sé» o canaliza la consulta si no hay datos.
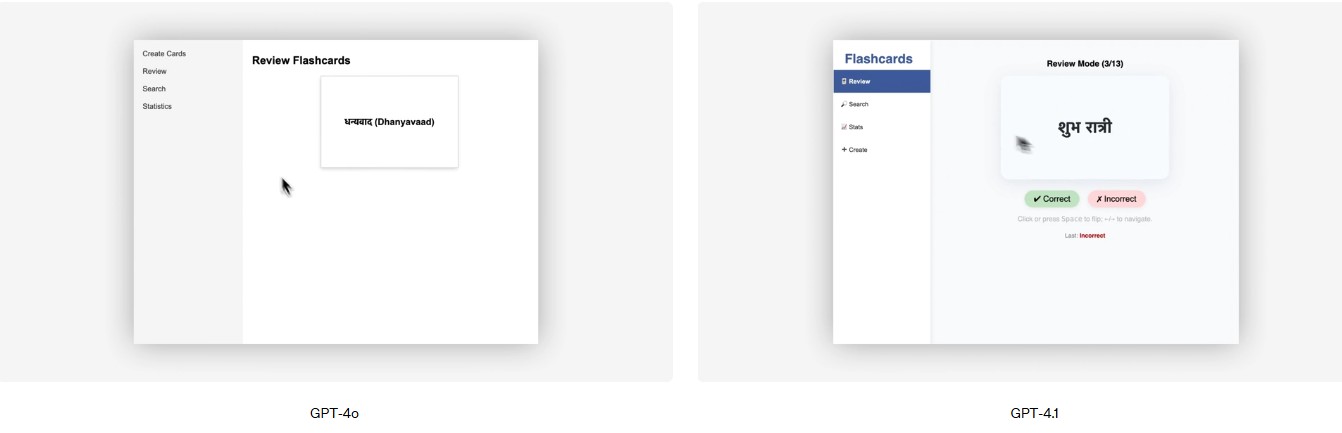
Cada categoría se evalúa en niveles de dificultad: fácil, medio y difícil. GPT‑4.1 sobresale especialmente en los niveles difíciles, con un 49% de precisión frente al 29% de GPT‑4o.
En el benchmark Scale’s MultiChallenge (evaluación desarrollada por Scale AI para medir la capacidad de mantener conversaciones realistas y complejas con múltiples turnos de interacción), GPT‑4.1 obtuvo un 38,3%, un salto de 10,5% respecto a GPT‑4o. Esta mejora se traduce en interacciones más naturales, reduciendo la necesidad de reformular indicaciones.
Esto es especialmente útil para construir agentes autónomos que interactúan con usuarios o sistemas, como asistentes virtuales, sistemas de resolución de incidencias, o agentes de escritura creativa.
Por ejemplo, empresas como Blue J y Qodo (especializadas en generación de código) han implementado GPT‑4.1 para generar documentos legales y resúmenes académicos con precisión, mientras que la herramienta de edición Windsurf y la agencia Thomson Reuters lo utilizan en entornos de desarrollo donde cada instrucción debe seguirse al pie de la letra.
Comprensión profunda de contextos largos
Todos los modelos de la familia GPT‑4.1 admiten una ventana de contexto de 1 millón de tokens, permitiendo procesar archivos de texto extremadamente largos. En la evaluación Vídeo-MME, GPT‑4.1 alcanzó un 72% en la categoría «long, no subtitles» (largo, sin subtítulos), una mejora del 6,7% respecto a GPT‑4o.
Esto permite nuevos casos de uso como el análisis completo de documentación técnica, la lectura de informes financieros de cientos de páginas, o la comprensión de guiones de vídeo o subtitulados con una sola consulta, identificando tendencias clave y proporcionando análisis comprensibles para la toma de decisiones estratégicas.
Además, gracias a esta capacidad, es posible construir agentes que operen de forma autónoma durante horas, manteniendo coherencia y precisión sin necesidad de reiniciar el contexto.
Generación de imágenes
Aunque los modelos GPT‑4.1 no son multimodales como GPT‑4o, han sido diseñados para integrarse eficazmente con herramientas de generación de imágenes, mejorando la coherencia entre texto e imagen. Esto permite a los desarrolladores crear aplicaciones que combinan descripciones textuales detalladas con representaciones visuales precisas, facilitando la creación de contenido multimedia atractivo y personalizado.
Por ejemplo, una aplicación puede utilizar GPT‑4.1 para generar descripciones detalladas de productos y luego, mediante una herramienta de generación de imágenes, crear representaciones visuales que coincidan con esas descripciones, mejorando la experiencia del usuario y la eficacia del marketing.
Foto: OpenIA